
Francesco Bonchi
Head of Intesa Sanpaolo AI Research
AI Innovator and Scientific Leader
Scientific leader bringing over 25 years of experience to the international AI and Data Science research communities. Spanning both rigorous academic research and industrial leadership, my career path is backed by a proven track record of translating foundational research into impactful industrial solutions and establishing globally-recognized research teams.
My expertise lies in driving large-scale research initiatives and aligning cutting-edge research with strategic business objectives. As a hands-on leader, I am deeply committed to mentoring researchers and cultivating a highly cooperative culture. My core research interests cover AI, machine learning, data mining, network science, and algorithmic fairness, with my work regularly appearing in top-tier venues such as NeurIPS, KDD, WWW, and VLDB.
📢 Latest News
- 2026: Papers accepted at ICLR 2026, AISTATS 2026, KDD 2026, and VLDB 2026
- January 2026: Launched Intesa Sanpaolo AI Research
- 2026: PC Chair of The Web Conf 2026 and of the Applied Data Science Track at ECML PKDD 2026
- 2026: Tutorial GNN Explainers 2.0: User-centric and Data Driven Insights at WSDM 2026
- 2025: Papers published at NeurIPS, KDD (x3), VLDB, IJCAI, ECML PKDD, and more...
- 2024: General Chair of KDD 2024 in Barcelona (together with Ricardo Baeza-Yates)
- 2023: Best AI-track paper award at EAAMO 2023
- 2022: Best Paper Award at The Web Conf 2022
Selected Research
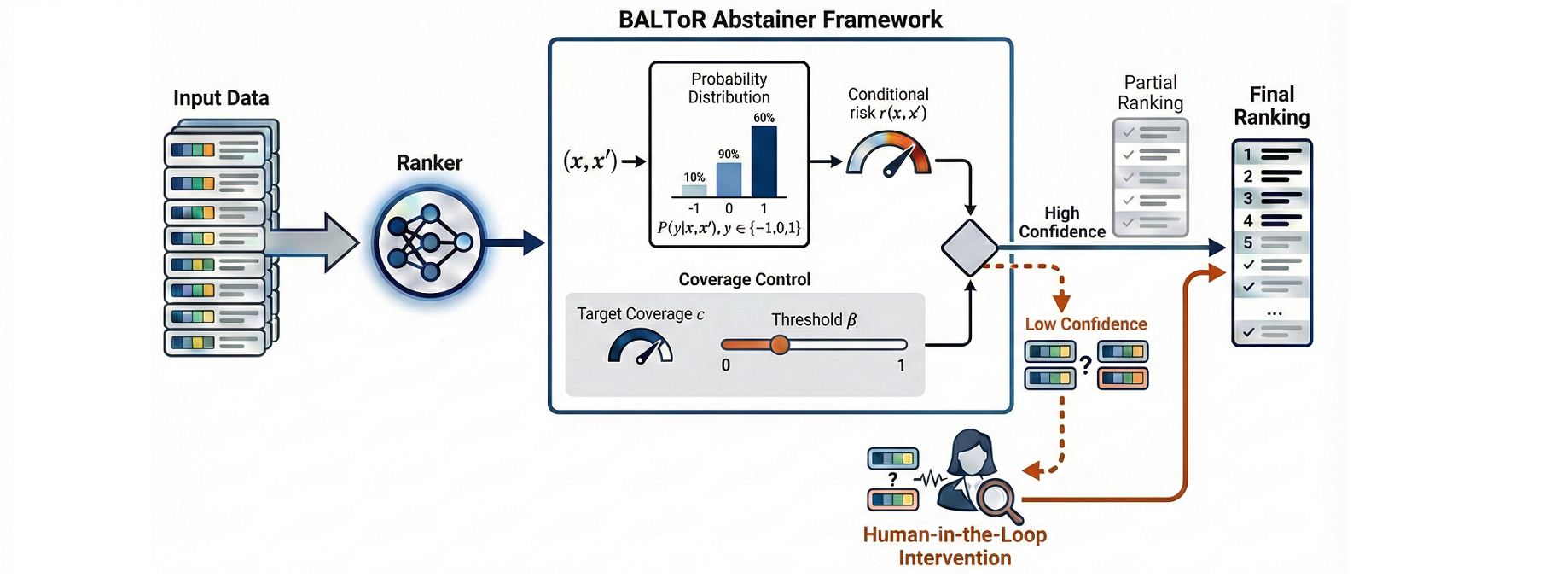
Bounded-Abstention Pairwise Learning to Rank (KDD'26)
Ranking systems influence decision-making in high-stakes domains like health, education, and employment, where they can have substantial economic and social impacts. This makes the integration of safety mechanisms essential. One such mechanism is abstention, which enables algorithmic decision-making system to defer uncertain or low-confidence decisions to human experts. This work introduces BALToR, a principled, bounded-abstention framework for pairwise learning-to-rank with ties. By thresholding the ranker’s conditional risk at a c-quantile level, BALToR selects which pairs to predict and which to abstain, targeting a fixed abstention budget.
Read more →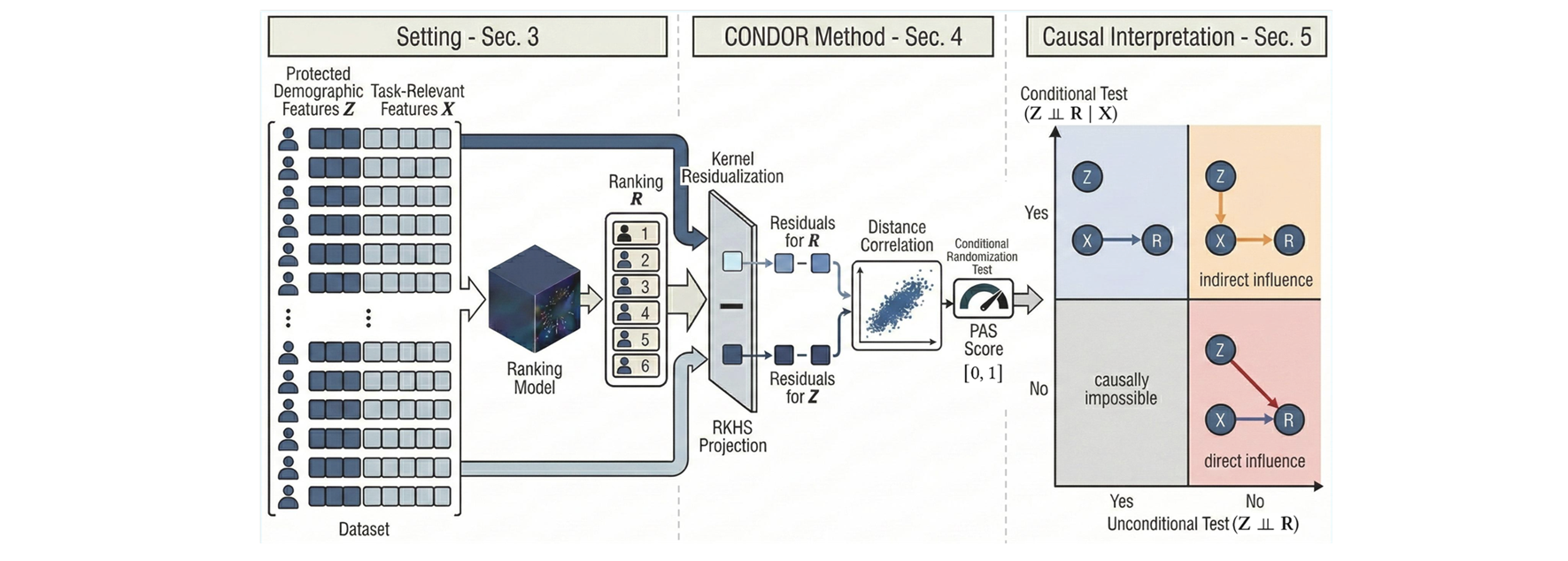
Auditing for Demographic Bias in Opaque Rankings (VLDB'26)
Given a ranking of individuals produced by a black-box, how can we audit the black-box assessing whether the order is driven by protected attributes (e.g., gender or race) rather than task-relevant features? To solve this problem, we introduce Condor (CONditional Distance-cOrrelation for Rankings), a model-agnostic audit framework that quantifies the residual dependence of a ranking on protected attributes. By combining this test with an unconditional independence test, auditors can achieve a comprehensive causal understanding of the protected attributes’ influence.
Read more →
Size-adaptive Hypothesis Testing for Fairness (NeurIPS'25)
When subgroup sizes vary widely, traditional fairness tests often fail, producing false alarms for tiny groups and missing real issues in larger ones. Our methodology - SAFT: Size-Adaptive Hypothesis Testing for Fairness - offers a rigorous, uncertainty-aware way to evaluate fairness.
Read more →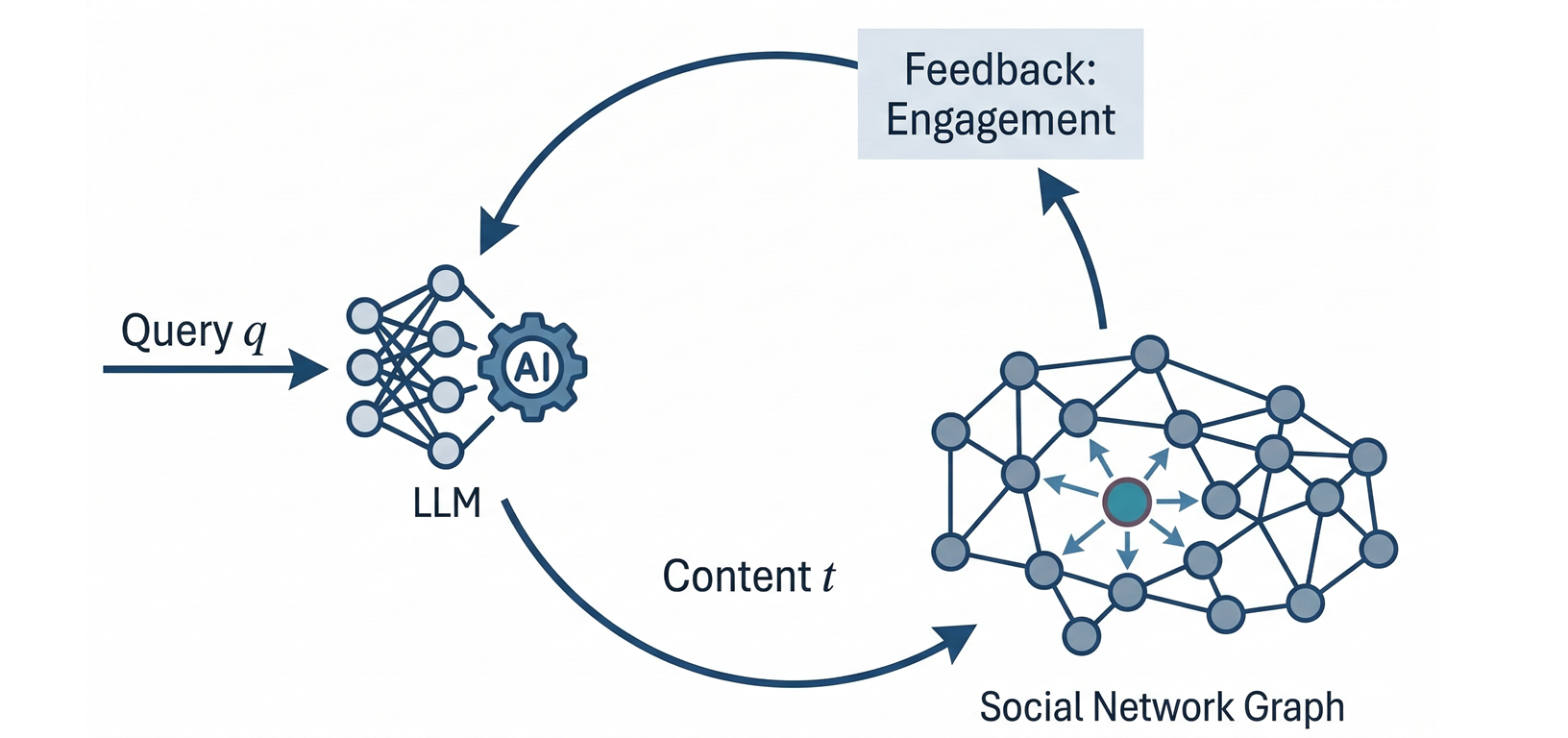
Engagement-Driven Content Generation with LLMs (KDD'25)
How persuasive are LLMs within social networks, not just in one-on-one settings? We introduce a novel Reinforcement Learning (RL) pipeline that empowers LLMs to generate high-engagement content for social platforms, without requiring costly, slow live experiments.
Read more →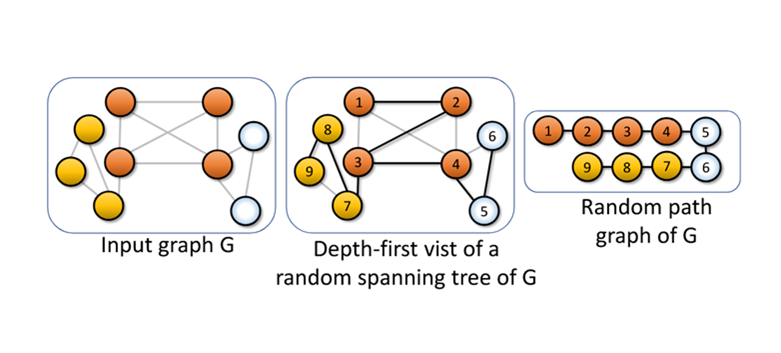
Training GNNs with Sequences of Random Path Graphs (KDD'25)
We introduce a scalable framework for training GNNs based on effective resistance, a standard tool in spectral graph theory. Our method progressively refines the GNN weights on a sequence of random spanning trees suitably transformed into path graphs which, despite their simplicity, are shown to retain essential topological and node information of the original input graph.
Read more →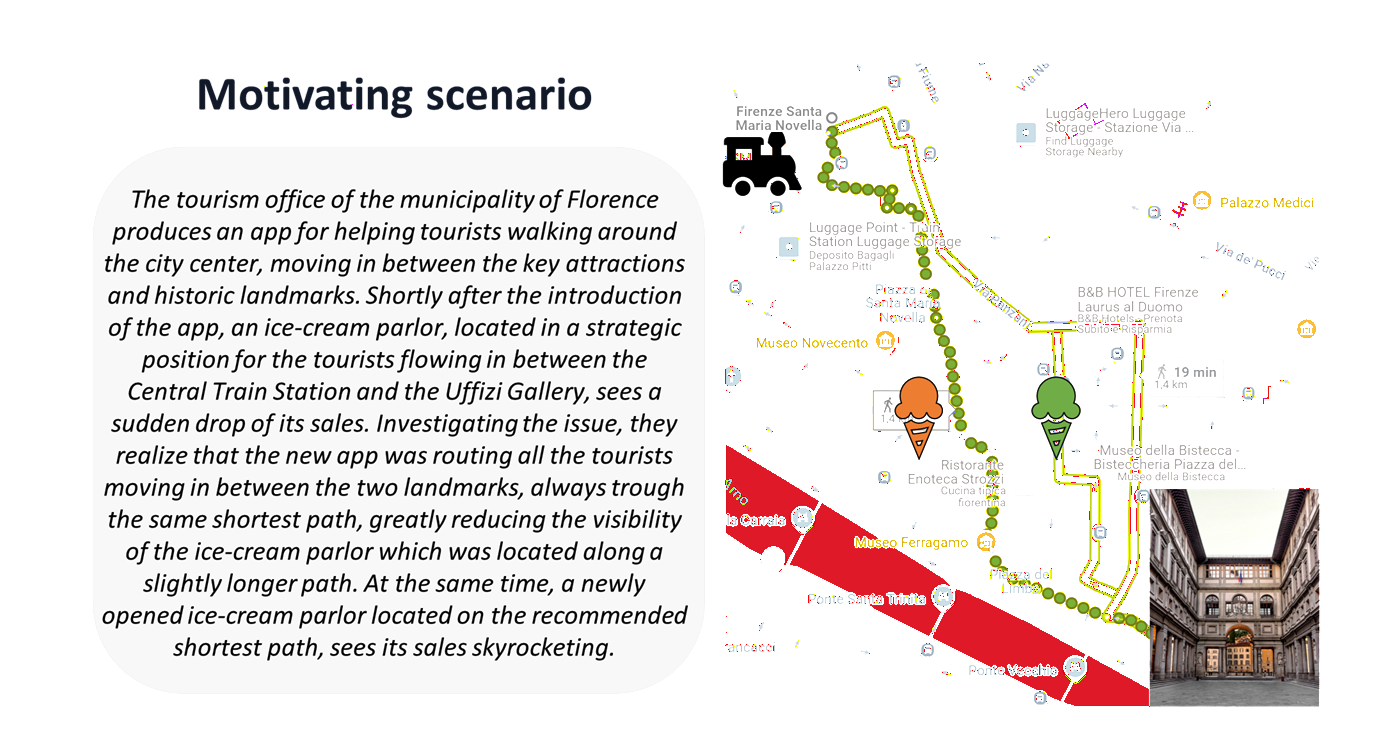
Node Fairness in Route Recommendation (VLDB'25)
We address the challenge of ensuring a fair distribution of visits among network nodes when handling a high volume of point-to- point path queries. In doing so, we adopt a Rawlsian notion of individual-level fairness exploiting the power of randomization.
Read more →